Introduction to Privacy Enhancing Technologies
Does data confidentiality or security provide protection for data privacy? Data security plays a crucial role in safeguarding data, but it doesn’t solely ensure data privacy. These terms are sometimes used interchangeably; however, they hold distinct meanings, both in semantics and in the associated requirements and regulations. While they are interrelated, each term encompasses distinct facets of data protection.
Data security specifically concerns the safeguarding of sensitive information, including financial, business, technology, IP, HR, etc., allowing access solely to authorized individuals or entities. It is highly critical to preserve data confidentiality while storing, processing, or transmitting sensitive data to prevent unauthorized access, disclosure, or tampering. On the other hand, data privacy pertains to the protection of users’ personal information. Despite measures taken to maintain the confidentiality of data, individuals can still be directly identified, at least by authorized individuals, or indirectly identified through correlations and inferences drawn from seemingly anonymized information. For example, consider a dataset devoid of explicit personal details but comprising unique combinations of location, age, and purchasing behavior. When cross-referenced with external publicly available information or other datasets, this could potentially lead to the identification of individuals. This identification can compromise users’ privacy, even if the primary data is kept confidential.
In addition, with the rise of data-driven approaches such as machine learning, new privacy threats have emerged, one of which is the membership inference attack. This attack targets machine learning models by attempting to discern if specific data samples were part of the training dataset used to build the model. By analyzing the model’s outputs or predictions, attackers aim to infer whether certain individual data points were included during training, potentially leading to privacy breaches.
For example, imagine a healthcare organization utilizing machine learning to build a predictive model for disease diagnosis based on patient health records. An attacker in this scenario wants to determine if specific individuals were part of the training dataset used for this model. He can achieve this by submitting queries to the trained model with specific data samples and analyzing the model’s response patterns. Through observing the model’s behavior-such as its confidence scores or prediction probabilities—regarding these queries, the attacker can deduce if the queried data aligns closely enough with the training data, thereby inferring whether those individuals were part of the dataset.
This method allows the attacker to breach the privacy of individuals whose information was used to train the model, potentially exposing sensitive health records without direct access to the original training dataset. As another example, consider a financial institution using machine learning to build a fraud detection model based on transaction histories. In this scenario, an attacker seeks to identify if specific users’ transaction data was included in the model’s training dataset. This topic has attracted so much attention in both academic and industrial fields that recently, NIST organized an award-winning competition focused on the use of Privacy-Enhancing Technologies (PETs) in data-driven approaches.
Protecting confidential and sensitive data, along with ensuring the privacy of users’ information, stands as an utmost priority for security teams. Privacy, being an extremely crucial subset of data protection, has gained immense significance under regulations like GDPR. These stringent guidelines not only emphasize the safeguarding of users’ privacy but also place specific obligations on companies to implement protective measures. Failing to meet these responsibilities not only poses potential risks to the confidentiality of data but could also result in severe consequences for businesses, ranging from legal penalties to damaged trust and reputation among users and stakeholders.
Data Peace Of Mind
PVML provides a secure foundation that allows you to push the boundaries.

Data and privacy protection vs. business/utility tradeoff
Figure 1 illustrates the tradeoff between data protection and utility. Increasing privacy measures frequently results in restricting the utility or value of data for analytical, research, or other beneficial purposes. For instance, consider the addition of random noise to data, aimed at preventing the re-identification of the data owner by exploiting available metadata or other deductions. While adding noise effectively prevents the disclosure of the data owner’s identity, it may simultaneously diminish the data’s usefulness due to the introduced distortion. Hence, a clear tradeoff exists between safeguarding data privacy and maintaining its utility, posing a significant challenge in balancing both aspects effectively.
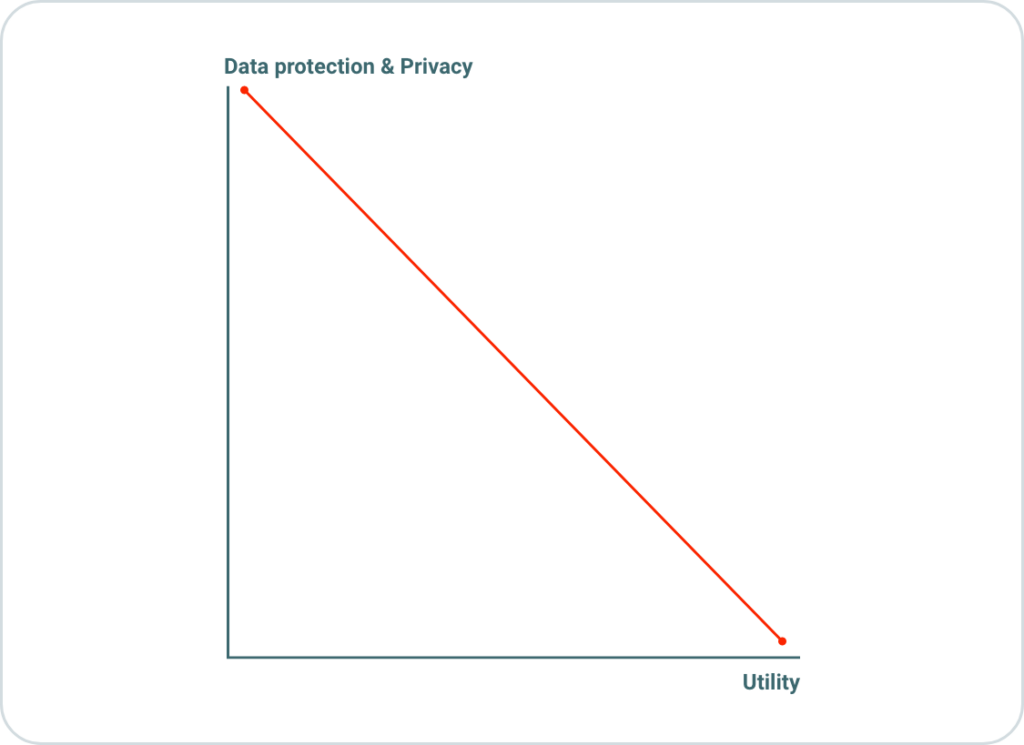
Figure 1: Tradeoff between data privacy and utility
On one hand, maximizing privacy involves stringent measures to protect personal information, limit its exposure, ensure anonymity, and maintain confidentiality. However, these protective measures, such as data anonymization or encryption, may reduce the richness or granularity of the data, which in turn could diminish its utility for various applications, especially in fields like research, analysis, or machine learning, where comprehensive and detailed data is often crucial.
On the other hand, maximizing utility involves collecting and using data in its most detailed, comprehensive form to derive the greatest possible insights, innovation, or value. However, this might come at the expense of compromising individual privacy if proper safeguards aren’t in place.
This is where PETs (privacy enhancing technologies) step in as pivotal solutions. As illustrated in Figure 2, PETs act as a bridge between the seemingly conflicting goals of maximizing both privacy and utility. These technologies offer innovative methodologies and tools that enable organizations to strike a balance between these two objectives.
PETs facilitate techniques like differential privacy, homomorphic encryption, secure multi-party computation, and more. These methods allow for the extraction of valuable insights or the execution of computations on data while preserving the confidentiality and privacy of individual information. By integrating PETs, organizations can retain the necessary granularity of data for advanced analytics, research, or machine learning applications without compromising individual privacy rights.
In essence, PETs serve as a critical keystone in achieving the harmonious coexistence of privacy and utility, enabling organizations to harness the full potential of data without compromising the confidentiality and privacy of individuals associated with that data.
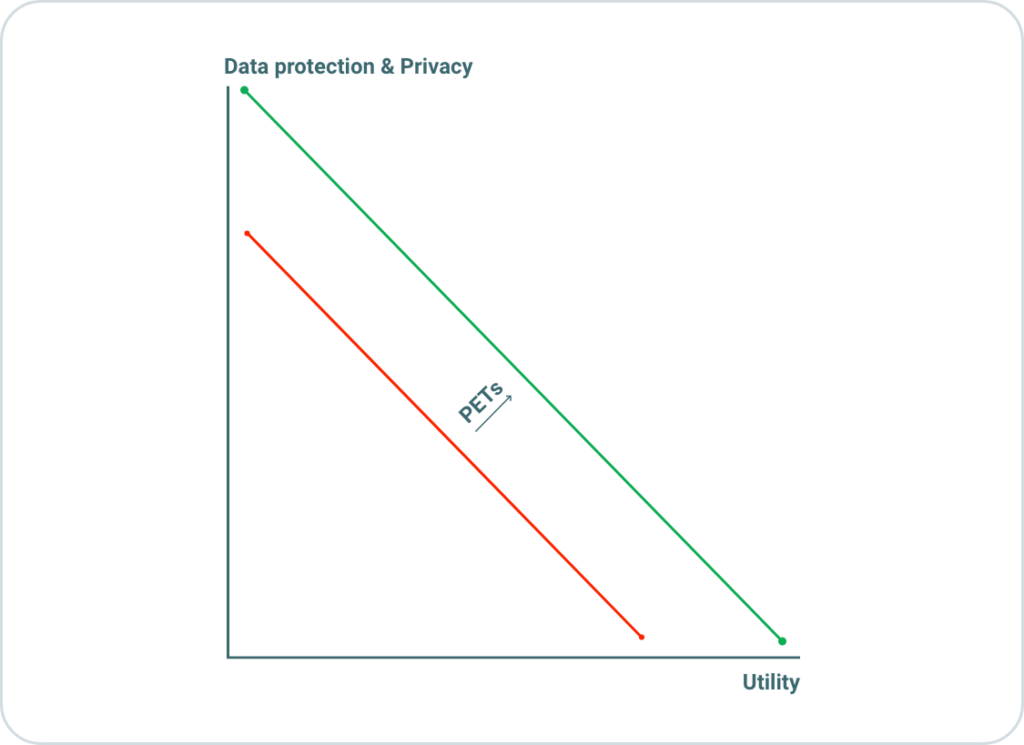
Figure 2: Enhancing both privacy and utility
PETs
Finding the right balance between privacy and utility is a significant challenge in today’s data-driven world. It often involves ethical considerations, legal compliance, and technological innovations to derive valuable insights while respecting individuals’ privacy rights. The main objective of PETs is to increase both privacy protection and data utility at the same time. Some popular PET approaches include:
- Masking: This technique involves removing or replacing personally identifiable information (PII) from a dataset to prevent the immediate identification of individuals associated with that data. This process typically involves removing identifiers (e.g., names, addresses, and phone numbers), generalization (e.g., exact ages might be grouped into age ranges), or replacing the original sensitive data with a standardized placeholder (e.g., credit card numbers may be replaced with asterisks). This approach helps maintain the structure and format of the data while obscuring the actual information.
- Homomorphic Encryption: This is a form of encryption that allows computations to be performed on encrypted data without decrypting it first, ensuring privacy during data processing. In traditional encryption methods, data needs to be decrypted before performing any operations or computations. However, with homomorphic encryption, it becomes possible to conduct mathematical operations directly on encrypted data, generating an encrypted result that, when decrypted, yields the same outcome as if the operations were performed on the unencrypted data.
- Differential Privacy (DP): This is a framework that adds noise or perturbation to datasets or query output, allowing the extraction of valuable insights without compromising individual privacy. It is even possible to apply these perturbations to a model’s internal coefficients, distorting results within the machine learning domain. The core concept of differential privacy lies in obscuring individual contributions within a dataset. When a query or computation is performed on a dataset, the output or result intentionally includes random noise, making it difficult to determine whether a specific individual’s data was part of the calculation.
For example, suppose we have a database containing information about individuals’ ages, and we want to derive descriptive statistics on this dataset without revealing any hint about the age of any particular person in the dataset. As a differential privacy measure, we might add a random value chosen from a probability distribution like Laplace or Gaussian distributions to each person’s age entry or to the query result. This noise should be the minimal amount required to conceal the individual’s contribution without altering the integrity of statistical results. Nonetheless, it’s essential to note the tradeoff between added privacy-preserving noise and the resulting accuracy distortion in data, known as the privacy-utility tradeoff.
- Secure Multi-Party Computation (SMPC): This is a cryptographic technique that enables multiple parties to jointly compute a function over their private inputs without revealing their individual inputs to each other. The main goal of SMPC is to perform computations while maintaining the privacy of each party’s data.
- Pseudonymization: Pseudonymization is a data privacy technique that involves replacing identifiable information within a dataset with artificial identifiers, aliases, or pseudonyms. The objective of pseudonymization is to protect the identities of individuals while still allowing data to be useful for certain purposes.
- Federated Learning: Federated learning is a machine learning approach that enables model training across decentralized devices or servers while keeping the data localized and private. It allows multiple devices or entities (such as smartphones, IoT devices, or different organizations) to collaboratively train a shared machine learning model without sharing their raw data.
Conclusion
In the realm of data security and privacy, the perpetual balancing act between safeguarding sensitive information and leveraging its utility for innovation persists. This delicate equilibrium, often referred to as the privacy-utility tradeoff, requires a thoughtful approach. Ranging from differential privacy to homomorphic encryption and pseudonymization, PETs, an arsenal of tools designed to empower this delicate balance, offer promising avenues to uphold privacy while harnessing the transformative potential of data. As we navigate this landscape, the next crucial step emerges: the deliberate selection and implementation of PETs. Choosing the right PET technology stands as a pivotal step towards not just protecting privacy but also fostering a future where data-driven progress thrives responsibly and ethically.
Selecting the most suitable Privacy Enhancing Technology (PET) relies on a multitude of factors, such as your specific data, use case, the level of privacy you aim to maintain, the desired utility of the information, and the regulatory landscape in which you operate. Factors like computational complexity, scalability, and integration capabilities also weigh into this decision-making process. To delve deeper into this crucial selection process and understand how to navigate the landscape of PETs effectively, stay tuned for our upcoming blog post that will provide comprehensive insights and a step-by-step guide on ‘How to Choose the Right PET Technology’ to suit your unique needs.