

Introduction
Personally identifiable information (PII) is any information that can be used on its own or with other data to identify, contact, or locate a single person. For instance, this could be an address, full name, gender, or phone number.
Many organizations share data with third parties for analysis and to gain more knowledge. However, it’s important to note that PII data should not be shared with third parties as it can significantly compromise an individual’s privacy. Additionally, personal data protection acts and regulations have become more stringent and mandated across specific regions and industries; therefore, organizations have no other option but to adopt and adhere to these regulations to keep PII data safe and avoid getting fined for noncompliance.

Additionally, as organizations grow, so does the amount of PII they process as part of their business processes. So, they need to adopt stricter techniques to preserve their PII and ensure data security and sharing.
This is where data masking comes into play. With data masking, companies can hide PII data from the actual dataset and share the dataset with third-party companies for analysis without infringing on data privacy. Not only that but in cases of cyber attacks, the PII data is kept intact as they are stored in a masked state. With effective use of data masking, you can make personally identifiable information indecipherable to unauthorized users, thus significantly reducing the risk of data breaches and allowing for safer data sharing.
So, let’s examine data masking in greater detail and explore techniques for adopting it.
What is PII Masking?
At its core, PII masking ensures that personally identifiable information is not readable by unauthorized parties by changing, replacing, or completely removing parts of the PII.
All techniques that will be discussed in this article follow the same principles. So, when data is shared with third-party companies, it can be processed without compromising the privacy of the individual and also remain safe in cases where PII data is breached, as masked data wouldn’t be of any significant value to the attackers.
PII Masking Techniques
Organizations employ various methods to mask the PII that they process or store. Here are some of the most commonly used PII masking techniques that can be used.
- Tokenization
- Encryption
- Anonymization
- Pseudonymization
- Shuffling
1. Tokenization
Tokenization is the process of substituting sensitive data with non-sensitive placeholders, known as tokens.
These tokens are randomly generated and hold no intrinsic value, effectively de-identifying the original data while preserving its format.
For example, let’s say we have a customer’s credit card number: 4532 7590 3454 5858. When this number is tokenized, it might be replaced with something like ABCD-1234-WXYZ-5678.
The customer’s actual credit card number does not get stored or transmitted through the business’s internal systems. Instead, the token representing this number is used.
When a transaction needs to be processed, the token is sent to the tokenization system, which swaps the token for the actual credit card number and processes the payment with the card number. After the transaction, only the token, not the card number, is stored for reference.
This means that tokenized transaction data can be shared for analysis as it doesn’t hold the card number.
How Tokenization Works
When PII, such as credit card numbers, social security numbers, or other sensitive data, is submitted, a tokenization system intercepts the data and replaces it with a token. The original data is then securely stored, typically in a separate, highly protected database or vault.
Benefits of Tokenization
Tokenization offers several key advantages in PII security:
- Enhanced Security: Tokenized data is meaningless to unauthorized parties, significantly reducing the risk of data breaches.
- Reduced Compliance Scope: Since tokenized data is not considered sensitive, it falls outside the scope of many regulatory requirements.
- Ease of Implementation: Tokenization can be seamlessly integrated into existing systems with minimal disruption.
- Data Integrity: The original data remains intact and accessible to authorized users when needed.
Use Cases of Tokenization
Tokenization finds application in various industries and scenarios, including:
- Payment Processing: Credit card numbers are tokenized to secure transactions, minimizing the risk of storing sensitive financial data.
- Healthcare: Medical records containing sensitive patient information can be tokenized to protect patient privacy while still allowing for efficient data analysis.
2. Encryption
Encryption is the process of converting plaintext data into ciphertext using cryptographic algorithms and keys.
For instance, consider this dataset:
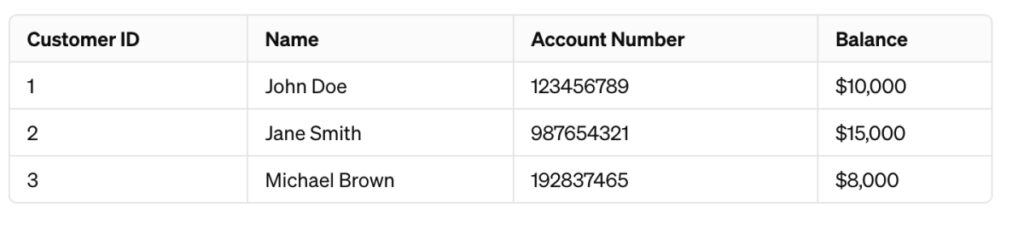
The columns “Account Number,” “Balance,” and “Name” are quite sensitive. So, you could encrypt it:

This transformation renders the data unreadable without the corresponding decryption key, ensuring confidentiality and integrity.
How Encryption Works
Encryption transforms readable data (plaintext) into unreadable data (ciphertext) using a mathematical process called encryption. This process involves using a special code, known as an encryption key, and an encryption algorithm to scramble the data.
Only someone with the correct decryption key can unscramble the ciphertext back into its original form (plaintext). This ensures the data remains private and secure, even if it’s intercepted during transmission or stored on a device.
Data Peace Of Mind
PVML provides a secure foundation that allows you to push the boundaries.

Benefits of Encryption
Here are some benefits that come with adopting encryption for PII:
- Enhanced Security: Encrypting data makes it unreadable to unauthorized users, reducing the risk of data breaches.
- Confidentiality: Encrypted data remains secure during transmission and storage, protecting sensitive information from unauthorized access.
- Data Integrity: Encryption detects and prevents unauthorized modifications, ensuring data integrity.
- Regulatory Compliance: Encryption helps organizations comply with data protection regulations such as GDPR, HIPAA, and PCI DSS.
Use Cases of Encryption
Since encryption is versatile, it can be used in almost all use cases within an organization.
- Healthcare: Encrypts patient records, like medical history and personal details, to protect PII.
- Financial Transactions: Secures banking activities, including credit card transactions, to safeguard PII, such as account numbers.
- Human Resources: Protects employee data like payroll information and evaluations in HR systems.
Note, in some cases, you could consider using a Hardware Security Module (HSM) to manage and protect the encryption key itself.
3. Anonymization
Anonymization aims to remove or alter personally identifiable information from datasets so that individuals cannot be re-identified.
For instance, consider the dataset below:

This dataset consists of a list of patients. For each patient, the age, ZIP code, and condition are maintained. However, if this were masked, it would look something like this:
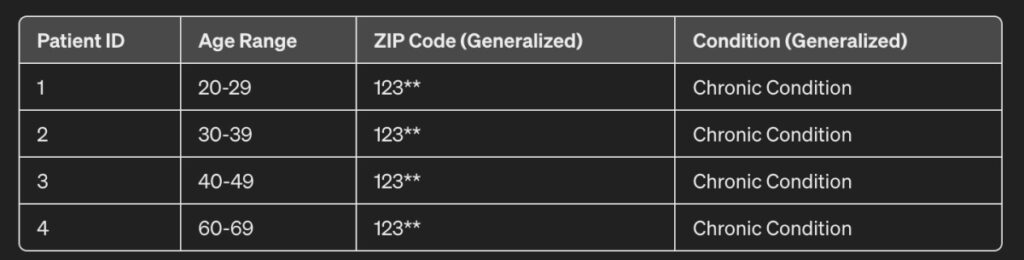
If observed closely, the following changes have been made:
- Age: Instead of precise ages, age ranges have been used (e.g., 20-29, 30-39, etc.).
- ZIP Code: Reduce the precision of the data by using only the first three digits.
- Condition: Generalize specific conditions into broader categories
By doing so, this data is still usable for analysis but preserves the privacy of the data owner.
How Anonymization Works
- Data Transformation: Anonymization involves transforming or removing identifying information from datasets. This can include masking or deleting direct identifiers such as names, addresses, and social security numbers.
- Generalization and Aggregation: Anonymization may generalize data by replacing specific values with broader categories (e.g., age ranges instead of exact ages). Aggregation combines individual data points into groups to prevent re-identification while still allowing for analysis.
- Randomization: Anonymization techniques may introduce randomness by perturbing data values or adding noise. This ensures that even if some information is retained, it cannot be linked back to specific individuals.
Benefits of Anonymization
Here are some benefits that come with adopting anonymization for PII:
- Data Sharing and Research: Anonymized data can be shared more freely for research and analysis purposes without compromising individual privacy. It enables collaboration and knowledge sharing while preserving confidentiality.
- Privacy Protection: Anonymization safeguards individual privacy by preventing individuals from being identified from datasets. It minimizes the risk of data breaches and unauthorized access to sensitive information.
Use Cases of Anonymization
Here are some popular use cases for anonymization in PII:
- Healthcare Research: Anonymization de-identifies patient data for analysis, enabling the study of disease trends and treatment outcomes without risking privacy.
- Market Research: Anonymization lets companies analyze consumer data without revealing personal information and identifying trends without compromising privacy.
4. Pseudonymization
Pseudonymization replaces or obscures identifying information with pseudonyms or aliases. Unlike anonymization, which renders data entirely unidentifiable, pseudonymization retains the potential for re-identification by using additional information kept separately.
For example, consider the dataset for sales:
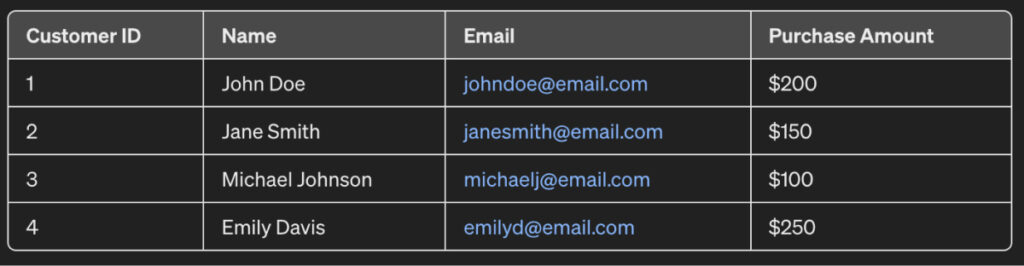
The “Name” and “Email” columns contain PII data. Therefore, this customer data must be kept private when sharing these sales records with third-party vendors.
Therefore, you can mask this dataset using pseudonymization to get a shareable dataset as follows:
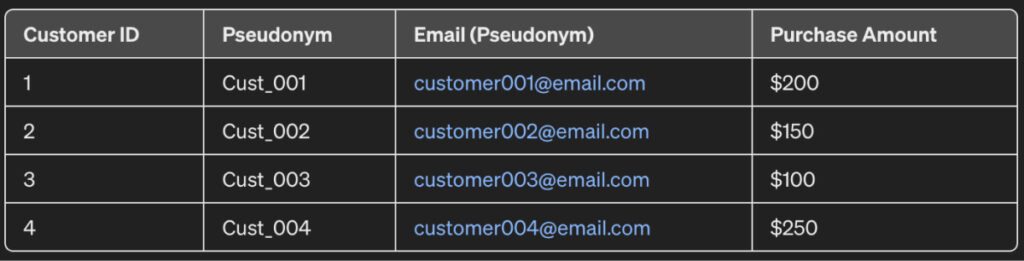
As observed, the email and the names have been overridden by aliases for each row. For instance, “John Doe” is now “Cust_001” and “johndoe@email.com” is “customer001@email.com”.
Because of these changes, the sales information cannot be linked to a particular customer.
How Pseudonymization Works
- Data Mapping: Initially, a mapping table is created, linking the original identifiers with pseudonyms. This table is securely stored separately from the pseudonymized data.
- Replacement of Identifiers: Identifying information, such as names or social security numbers, is replaced with pseudonyms in the dataset. This process maintains the structure and format of the data while obscuring sensitive details.
- Storage of Mapping Table: The mapping table associating pseudonyms with original identifiers is securely stored. Access to this table is restricted to authorized personnel, ensuring that re-identification is possible only for those with proper permissions.
Benefits of Pseudonymization
Here are some benefits that come with adopting pseudonymization for PII:
- Data Utility: Pseudonymized data retains its usefulness for analysis and research while complying with privacy regulations. It allows organizations to derive insights from data without compromising individual privacy.
- Compliance with Regulations: Pseudonymization facilitates compliance with data protection regulations such as GDPR (General Data Protection Regulation) and HIPAA (Health Insurance Portability and Accountability Act) by reducing the risk of identifying individuals from data sets.
Use Cases of Pseudonymization
Here are some popular use cases for pseudonymization in PII:
- Government and Research: Pseudonymization anonymizes sensitive datasets for statistical analysis and policy development, ensuring privacy while supporting evidence-based decision-making.
- Financial Services: Pseudonymization protects customer data in the financial sector, enabling transaction analysis and fraud detection without compromising privacy.
5. Shuffling
Shuffling randomizes the order of data elements within a dataset. By rearranging the sequence of data records, shuffling prevents the identification of individuals or patterns within the dataset.
For instance, consider the dataset below that illustrates the salary information of a set of employees:
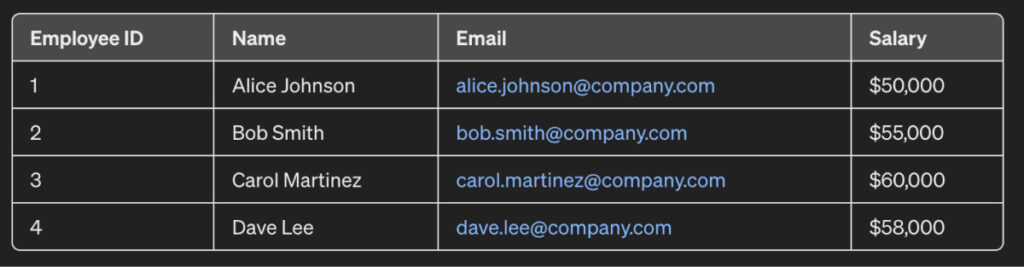
Each salary corresponds to an employee who can be contacted via email and identified by name. If an organization is sharing salary records for analysis, the employee information should not be visible as salary is often a sensitive piece of information to an employee and should not be disclosed to other people as to who is earning how much.
Therefore, you can shuffle this dataset to mask the PII data to create the following output:

As you can see, the names and emails aren’t the same. The characters in the name and email have been jumbled, and it’s impossible to figure out who the salary records belong to.
How Shuffling Works
- Randomization: Shuffling involves randomly reordering the data records within a dataset. This process ensures that the original order of the records is lost, making it challenging to identify specific individuals or relationships between data points.
- Data Integrity: Despite the randomization, shuffling preserves the integrity of the dataset by maintaining the same data records and attributes. Each data element retains its original value, but its position within the dataset is altered.
Benefits of Shuffling
Here are some benefits that come with adopting shuffling for PII:
- Enhanced Privacy: Shuffling protects individual privacy by obscuring the original order of data records and preventing the identification of specific individuals or sensitive information.
- Data Diversity: Shuffling introduces randomness into the dataset, increasing the diversity of data patterns and reducing the risk of unintended bias or discrimination in data analysis.
- Data Security: Shuffling enhances data security by making it more challenging for unauthorized users to decipher patterns or extract sensitive information from the dataset.
Use Cases of Shuffling
Here are some popular use cases for shuffling in PII:
- Data Mining: Shuffling is used in data mining and machine learning applications to ensure the privacy and security of sensitive datasets while still allowing for meaningful analysis and pattern recognition.
- Market Research: Shuffling is employed in market research to anonymize survey data and consumer feedback, protecting individual privacy while enabling trend analysis and market segmentation.
- Genomic Data Analysis: Shuffling is used in genomic data analysis to protect the privacy of individuals’ genetic information while allowing researchers to identify genetic markers and patterns associated with diseases or traits.
Best Practices For PII Masking
Understanding the best practices for PII masking is crucial for defining a secure baseline for PII processing.
- Understand Regulatory Requirements: Organizations must familiarize themselves with relevant data protection regulations, such as GDPR, HIPAA, or CCPA, to ensure compliance with legal obligations regarding PII handling and masking.
- Implement a Layered Approach: By using a combination of masking techniques, such as tokenization, encryption, pseudonymization, and anonymization, you’re providing multiple layers of protection. This approach should make you feel reassured and confident in the security of your PII and data.
- Selective Masking: Determine which elements of PII need to be masked based on their sensitivity and the specific use case. Not all data fields may require masking, so focus on protecting the most sensitive information.
- Secure Storage of Masked Data: Ensure that masked data is stored securely, whether in databases, backups, or during transmission. Implement encryption and access controls to prevent unauthorized access to both the original and masked data.
- Maintain Data Consistency: Masked data should retain its format and structure to maintain usability for legitimate purposes such as analytics and testing. Verify that masked data remains consistent and meaningful for authorized users.
- Regularly Review and Update Masking Policies: By periodically reviewing and updating your masking policies and techniques, you can stay ahead of evolving threats, regulatory changes, and technological advancements. This proactive approach should make you feel in control and confident in your PII masking practices.
Wrapping Up
It is essential to understand that every use case for PII masking within an organization will require a specific PII masking technique; these techniques are not a silver bullet for all use cases. However, implementing these techniques in large-scale organizations will be challenging due to the existing processes and systems that will need to work with this masked data.
Therefore, organizations must choose suitable PII masking tools and techniques to effectively mask and handle data without compromising the system’s performance or reliability.
It’s important to understand each technique and how it relates to your requirements. Based on that, the best PII masking technique can be selected. Additionally, your organization can choose to adopt more than one technique at a time if necessary.
By doing so, the data that are processed within an organization can be shared with third-party companies for analysis without the worry of compromising the privacy of the user to whom the data belongs.
Thank you for reading.









