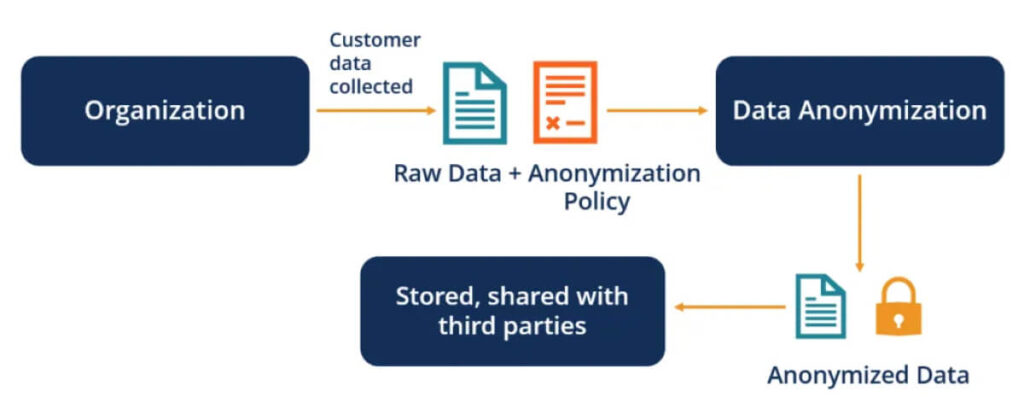
Almost every organization that works with data anonymizes it before using or sharing it with a third party.
Data is vital to a person and can be used to make various links to them.
For instance, if you collect data on the times that a set of people leave their home vacant and share it with a third party along with the residence address, it might be a threat to the homeowner as they might get robbed in that window.
This is exactly where data anonymization comes into the picture. As shown above, data anonymization is a process that removes personal or identifying information (PII) from a raw dataset to protect user privacy.
Use Cases of Data Anonymization
Data anonymization is often used in industries that deal with sensitive data, such as finance, healthcare, insurance, and governments.
Lately, it’s become a necessity in countries operating under the European Union (EU) as the GDPR policy enforces companies to adopt data anonymization of stored data on people living in the EU.
Upon anonymization, data is no longer subject to GDPR, which allows businesses to use the data for broader use cases without the limitations of data protection rights.
Additionally, the healthcare sector uses the HIPAA act and, as a result, must be bound by it to protect patient privacy at all times. Therefore, they are required to anonymize the patient data before sharing it with third parties such as research centers.
Data Anonymization Techniques
For organizations looking to implement data anonymization into their data processing workflow, there are several techniques to consider:
Generalization
Generalization is a technique that eliminates different parts of the data to make it less identifiable while preserving its accuracy.
For instance, consider the dataset below:

For each patient, the age, ZIP code, and condition are maintained. However, if this was generalized, it would have an output as follows:
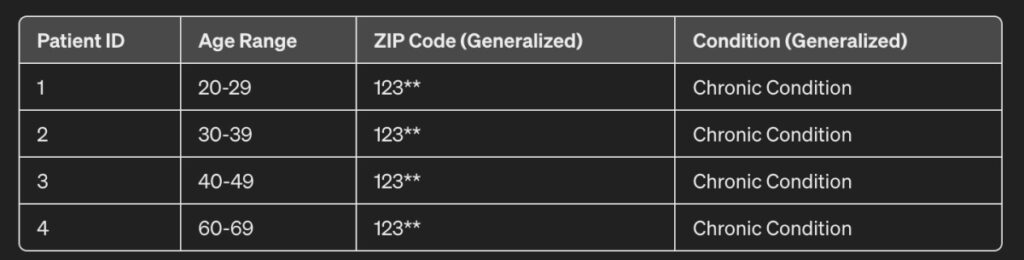
If observed closely, the following changes have been made:
- Age: Instead of precise ages, age ranges have been used (e.g., 20-29, 30-39, etc.).
- ZIP Code: Reduce the precision of the data by using only the first three digits.
- Condition: Generalize specific conditions into broader categories
Doing so protects individual privacy by making it difficult to link anonymized records with specific individuals while still allowing the dataset to be useful for analysis.
Perturbation
This technique slightly modifies a dataset while preserving the overall data integrity for analysis by adding random noise to data or altering the data slightly to prevent individuals from being identified.
For example, consider the dataset:
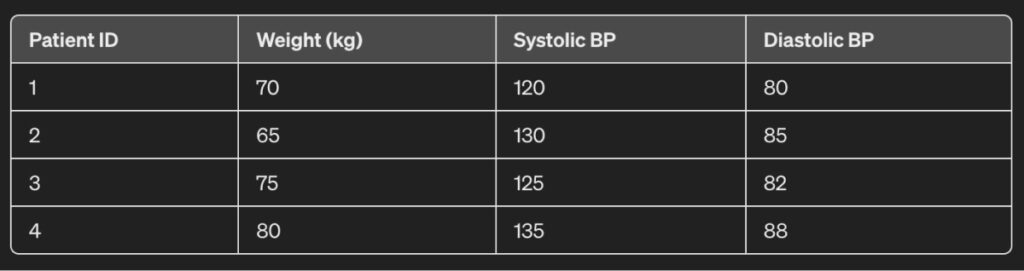
Each patient’s weight and blood pressures are taken.
If this dataset was anonymized using perturbation, it would create an output:
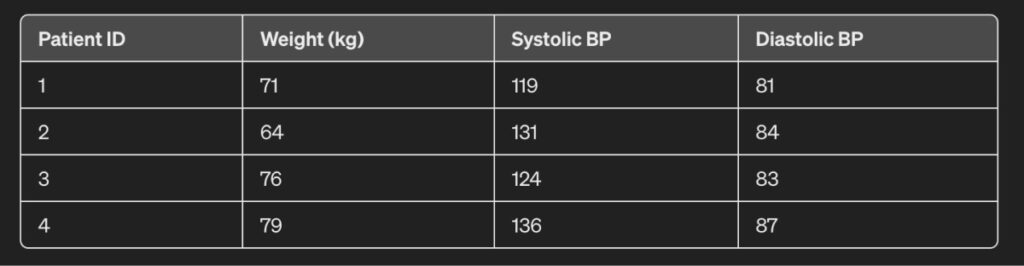
As observed, the weight, systolic and diastolic BP have been manipulated slightly in a random manner.
But, note that overusing this approach can make the data useless for analysis as they are far off from the real values.
Pseudonymization
This approach replaces private identifiers with fake identifiers or pseudonyms.
For example, consider the dataset for sales:
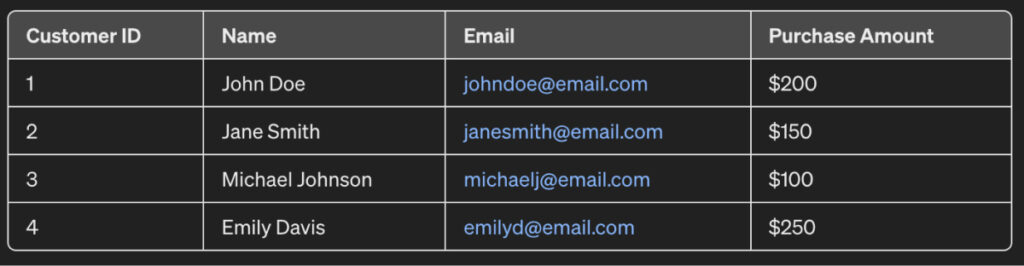
As observed, the name and email contain PII data. When sharing these sales records with third-party vendors, it’s important that the customer data be kept private. Therefore, pseudonymization can be done and would result in an output as:
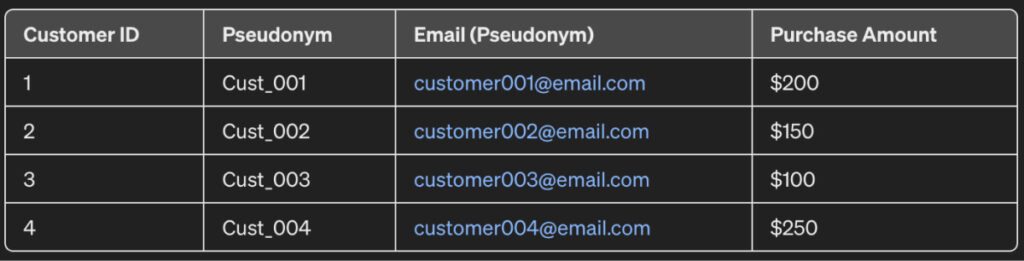
As observed, the email and the names have been overridden by aliases for each row. For instance, “John Doe” is now “Cust_001” and “johndoe@email.com” is “customer001@email.com”.
Because of these changes, the sales information cannot be linked back to a particular customer.
Scrambling
This approach involves jumbling the characters in a sensitive field to make it impossible to recreate.
For instance, consider the dataset below that illustrates the salary information of a set of employees:
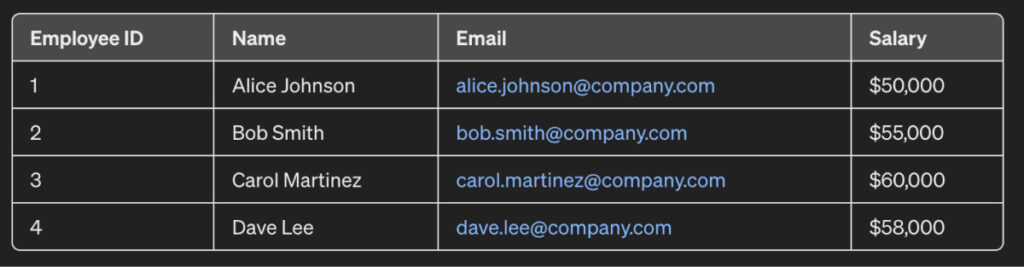
As observed, each salary corresponds to a particular employee who can be contacted via email and identified by their name. When sharing salary records for analysis, it should not be disclosed to other people as to who is earning how much.
Therefore, this data is anonymized using scrambling to create the following output:

Now, if observed closely, it’s noticeable that the name and emails aren’t really the same. The characters in the name and email have been jumbled, and it’s impossible to figure out who the salary records belong to.
Synthetic Data
This approach leverages machine learning and deep learning algorithms to generate synthetic data by analyzing the existing data. For example, algorithms like SMOTE generate synthetic data based on existing data.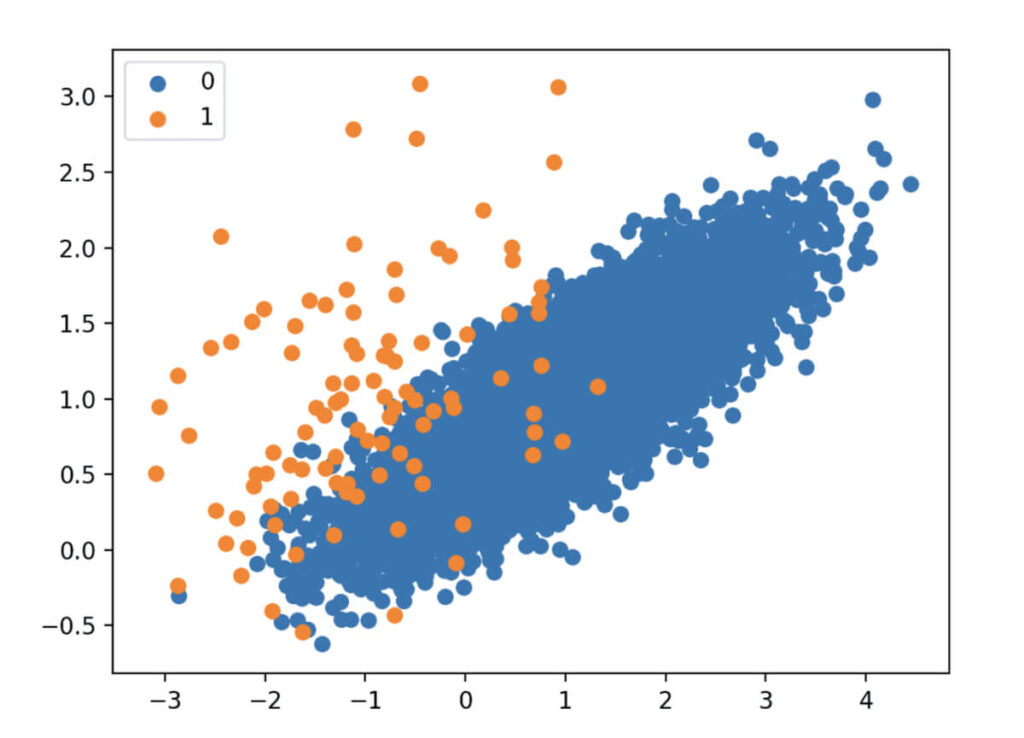
An initial dataset might look as shown above. There can be a different set of instances for a set of data items. There might be a need to create more data for the “Orange” class without duplicating data. So, SMOTE can be applied, and the output will change as follows:
SMOTE will learn the existing data and will create new data that doesn’t really reflect any living person. By doing so, the data isn’t duplicated, nor the privacy isn’t compromised as it’s all artificial.
Choosing The Right Data Anonymization Technique
Choosing the best data anonymization tools depends on the complexity of the project and the programming language in use.
For example, a doctor analyzing heart patient data will have different requirements than a data scientist analyzing banking customer transaction data.
Overall, the technique chosen should be compliant with GDPR and offer interactivity capabilities that help analysts query data dynamically via an interface with a one-time initial setup.
Data Peace Of Mind
PVML provides a secure foundation that allows you to push the boundaries.

The Difference Between Data Anonymization and Data Masking
Two words that are often used together but aren’t the same are:
- Data Anonymization
- Data Masking
Based on the techniques for data anonymization, it’s clear that the transformation done to the data cannot be reversed. But, with data masking, it’s more about temporarily hiding the data and then reversing it back to its original state.
But you can leverage the two concepts together and mask anonymized data. This adds another layer of security to data anonymization by masking certain pieces of data and only showing the most relevant pieces of data to data handlers who are explicitly authorized to see those specific pieces of relevant data.
This facilitates safe application testing wherein authorized testers see only what they need to see.
The Best Practices For Data Anonymization
The best approach to anonymization is to have multiple layers of defense.
In big data analytics, it’s recommended to have more than one layer of anonymization to protect against de-anonymization attacks.
Therefore, it’s important to implement these best practices when anonymizing data:
- Database activity monitoring: To provide real-time alerts on policy violations in data warehouses.
- A database firewall: To evaluate known vulnerabilities and block SQL injections.
- Data discovery: To determine where data resides
- Data classification: To identify the quantity and context of data on-premises and in the cloud.
- Data loss prevention software: To detect potential data breaches by inspecting sensitive information while in use, in motion, and at rest.
Conclusion
Data anonymization is a vital process in many industries. It’s important to preserve the privacy of the user and to abide by the restrictions enforced by bodies such as GDPR and HIPAA.
Therefore, always anonymize data and make sure it can’t be linked back to its owner after sharing it with a third party.