

What is Data Anonymization?
In the age of data-driven decision-making, the value of data is immeasurable. Businesses, healthcare organizations, and governments alike rely on data to gain insights, optimize operations, and make informed choices. The need to safeguard sensitive information has given rise to data anonymization methods to protect individual privacy while still harnessing the power of data. In this article, we will explore the art of data anonymization, the main data anonymization methods, the challenges, and a useful case study. In particular, we will look at how a startup that uses generative AI to provide health-related services applies a specific data anonymization technique to protect sensitive data.
In this article:
- Definition of data anonymization
- Why do you need to anonymize data?
- Data anonymization use cases
- What data should be anonymized?
- Data anonymization techniques
- Challenges in data anonymization
- Differential Privacy and the Privacy Gradient
- Best practice in data anonymization
- Which data anonymization techniques do you need?
- Case Study
- Future Trends in data anonymization
- Conclusion
Definition of Data Anonymization
To anonymize means “to remove identifying information so that the original source cannot be known.”1 In particular, Iso Standard 29100:2011 defines data anonymization as:” a process by which personal identifiable information (PII) is irreversibly altered in such a way that a PII principal can no longer be identified.”2
The primary objective of data anonymization is to safeguard the privacy and confidentiality of individuals while enabling the use of data for legitimate purposes such as research, analysis, and decision-making. Essentially, it aims to find a balance between the necessity for data access and the protection of personal information (refer to concepts like Differential Privacy and the Privacy Gradient).
However, as discussed later, data anonymization is not foolproof, and there is a risk of de-identification (refer to Challenges in data anonymization). This is why each data anonymization technique we will explore has its own set of advantages and drawbacks, catering to specific needs.
Why Do You Need to Anonymize Data?
The key objectives of data anonymization include:
- Privacy Protection: ensuring that an individual’s identity remains indiscernible from the data, thwarting unauthorized access to personal information. For instance, when the customer service team accesses client data, only specific information is visible, while other details remain masked.
- Data Utility: preserving privacy while maintaining the usefulness of data for analysis and decision-making. For example, two digital marketing agencies can share anonymized data to create targeted offers based on their common data.
- Compliance: assisting organizations in adhering to data protection laws and regulations, such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), and the Health Insurance Portability and Accountability Act (HIPAA), a US regulation governing private health information (PHI) in the healthcare industry, ensures compliance and protection of sensitive data.
Data Anonymization Use Cases
Here’s a breakdown of common scenarios where data anonymization is applied:
Medical and market research
- Sharing datasets for research: researchers can share data while safeguarding the privacy of study participants, like anonymizing patient data in clinical trials.
- Market research: companies can share customer data with market research firms for analysis of customer behavior, preferences, and demographics without disclosing individual identities.
Testing and development
- Test data: anonymized data serves for software testing and development without exposing sensitive customer information.
- Training machine learning models: anonymized data is utilized to train models, particularly in cases where privacy regulations are in place.
Financial services
- Credit risk assessment: utilizing anonymized financial data to assess credit risk and enhance lending decisions.
- Detecting fraudulent activities: anonymized transaction data aids in identifying patterns of fraud and illegal activities without compromising customer privacy.
Employee analytics
Anonymized HR data provides insights into employee performance, engagement, and well-being while upholding individual privacy.
IoT and smart devices
Anonymizing data from IoT devices for analysis, such as improving product performance or detecting anomalies, without compromising user privacy.
What Data Should Be Anonymized?
Determining the data that requires anonymization depends on specific contexts, privacy regulations, and the objectives of data processing. In a general sense, sensitive data and any information that can lead to the direct or indirect identification of individuals should undergo anonymization. To simplify, we can categorize sensitive information as follows:
PII (personal identifiable information)
Data that is unique or close to unique for a particular individual. This usually includes full name, email address, gender, mailing address, IP address, social media profile, phone number, social security number, credit card number, birthday, health records, or biometric data (i.e., fingerprints, iris scan).
Person-related data
Data that relates to a person but doesn’t fall under PII. This could be anything related to their personhood, including interests, beliefs, locations, and online and offline behaviors and activities.
Proprietary and confidential data
Data deemed sensitive for contractual or business-related purposes. Its release would endanger a business or other legal relationship or agreement.
Data Peace Of Mind
PVML provides a secure foundation that allows you to push the boundaries.

Data Anonymization Techniques
As per Article 29 Working Party’s Opinion 05/20143 on data anonymization techniques, it’s crucial to view data anonymization not as a singular, unified approach to data protection but rather as a collection of diverse techniques and methods.4 These methods aim to safeguard sensitive data by permanently concealing the original content of the dataset. The selection of an anonymization method depends on the nature of the data and its intended use. Several common methods include:
Data Masking and de-identification
Data masking involves replacing sensitive information with fictional or random data while preserving the structure and format of the original dataset. De-identification techniques, on the other hand, remove or generalize identifying attributes, such as names or social security numbers. Both methods help protect the privacy of individuals within the dataset.
Pseudonymization
It involves replacing sensitive data with a pseudonym or token, which can be reversed with a key (mathematical). This technique is ideal when used only internally by a small group of individuals who may require privileged access. For example, a customer support team that needs to see customer details but likely does not need access to all of them.
Aggregation and generalization
Aggregation combines multiple records into a single summary record, reducing the granularity of the data. Generalization involves replacing specific values with broader categories or ranges. These methods are particularly useful for preserving the overall statistical properties of the data while reducing the risk of re-identification.
Randomization techniques
Randomization techniques introduce noise into the data by adding random values or perturbing existing values. This makes it challenging to identify individuals while still allowing for useful analysis. Methods like k-anonymity and l-diversity are based on these principles.
Differential privacy
Differential privacy is a formal framework that quantifies the amount of privacy protection provided by a data anonymization method. It introduces controlled noise into the data to ensure that individual records cannot be distinguished, even if an attacker possesses auxiliary information. Differential privacy is gaining prominence in privacy-preserving data analysis.
Cryptographic approaches
Homomorphic encryption (HE) and secure multi-party computation (SMC) are cryptographic techniques that enable data analysis on encrypted data. These methods allow organizations to perform computations on sensitive data without ever decrypting it, thus preserving privacy.
Synthetic data
Synthetic data refers to artificially generated data that mimics the characteristics of real, original data but does not contain information about real individuals or entities. It is often used as a privacy-preserving alternative to real data for various purposes, such as testing, development, research, or sharing insights while protecting sensitive information. Synthetic data can be generated through various methods and algorithms.
Challenges in Data Anonymization
While data anonymization is crucial for privacy protection, it comes with its own set of challenges:
Re-identification risks
A significant challenge in data anonymization is the potential for re-identification. This involves uncovering the identity of an individual who possesses either directly identifying information (such as a full name or social security number) or quasi-identifying information (like age or approximate address) within a dataset. Despite anonymization efforts, attackers with additional information or the ability to exploit data patterns can sometimes re-identify supposedly anonymous data. A notable instance is the Netflix Prize Attack in 2007, where two data scientists successfully re-identified a database of over 480,000 names that Netflix had anonymized.5
Information loss and utility trade-offs
As data is anonymized, some level of information is inevitably lost. Striking the right balance between privacy and utility is challenging. Overzealous anonymization can render data useless, while too little protection exposes individuals to privacy risks.
Algorithm selection
Choosing the appropriate anonymization technique depends on the data and the specific use case. Selecting the wrong algorithm can lead to inadequate privacy protection or excessive data distortion.
Differential Privacy and the Privacy Gradient
As previously mentioned, it’s essential to recognize that anonymization is not foolproof. Consequently, one might wonder about the purpose of anonymization when there’s no absolute assurance of complete privacy. To approach this matter effectively, it’s crucial to consider how we can quantify the residual information that can be gleaned after the anonymization process.
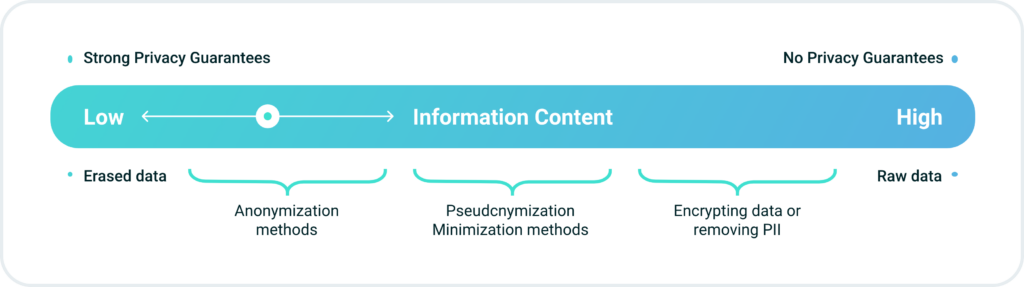
A pivotal moment in this thought process was the groundbreaking work by Cynthia Dwork and several other researchers.6 They demonstrated that, from a mathematical and logical standpoint, the concept of fully anonymized data release, as defined in the dictionary, is practically unattainable. Hence, the focus shifted from the question of “How can we anonymize data?” to the more pertinent query of “How can we assess the extent of privacy loss when data is disclosed? “This shift introduces the concept of a privacy spectrum, or privacy gradient (see diagram below).
In fact, the only way to guarantee complete privacy is to either delete all data or refrain from collecting it in the first place. However, data is indispensable for problem-solving. Framing privacy as a continuum allows us to better define our requirements. We can ask ourselves questions like, “To what extent am I willing to compromise privacy to address this issue?” and “How much privacy can I preserve while still obtaining meaningful answers to my inquiries?”
Differential Privacy emerges as a valuable tool for assessing information disclosure and finding a reasonable equilibrium between problem-solving and upholding individual privacy. Today, Differential Privacy is widely regarded as the gold standard in the field of anonymization.
In any case, even when applying data anonymization processes, it’s important to limit the amount of anonymized data disclosed to the public and to stick to the data minimization approach. In this way, you minimize the risk of this data set being matched with any kind of public records.
To help reason about these questions, Katharine Jarmul, a privacy activist and data scientist, has crafted a concise diagram illustrating the dynamic relationship between privacy and information. Positioned on the far left is the realm of absolute privacy, where all data is deleted, translating to zero information. Conversely, on the far right lies the domain of absolute information, signifying zero privacy, especially when the data is inherently sensitive.7
Along the diagram are various privacy technologies strategically placed to offer reasonable privacy guarantees. This visual representation assists in navigating the nuanced landscape between preserving privacy and accessing meaningful information.
Best Practice in Data Anonymization
To overcome the challenges and ensure effective data anonymization, organizations should follow best practices, including:
- Risk assessment
Begin with a comprehensive risk assessment to identify the potential privacy risks associated with the data. This assessment helps in determining the appropriate anonymization techniques to apply. - Data minimization
Collect and retain only the data that is necessary for the intended purpose. Reducing the amount of sensitive information in the dataset minimizes the potential impact of a data breach. - Privacy impact assessments
Conduct privacy impact assessments to evaluate the potential privacy implications of data processing activities. These assessments help in identifying and mitigating risks. - Data retention policies
Implement data retention policies that specify how long data will be stored. This reduces the risk of exposure and limits the impact of any potential data breaches.
Which Data Anonymization Techniques Do You Need?
Despite direct and quasi-identifiers being removed in one way or another, each of the following methods is remarkably effective at maintaining the contextual information of the original data. However, each one has its advantages and drawbacks.
We have drawn a table to help you with your decision-making:
| Technique | Re-identification Risks | Naturalness8 | Example Use Cases |
|---|---|---|---|
| Data Masking | Moderate to High | Can distort data naturalness in some cases | Healthcare data sharing, privacy in research |
| Pseudonymization | Low to Moderate | Preserves natural data structure | Patient record management, GDPR compliance |
| Aggregation | Low | Aggregated data may be less natural | Statistical analysis, data summarization |
| Randomization | Low to Moderate | Data may appear less natural due to noise | Statistical disclosure control, privacy in surveys |
| Differential Privacy | None to Low | May introduce noise that affects data naturalness | Statistical analysis, census data disclosure, privacy in surveys, privacy-preserving data sharing, machine learning models training |
| Cryptographic Approaches | Moderate | Can preserve natural data distribution | Secure data transmission, confidential data storage |
| Synthetic Data | Low to Moderate | May lack natural data distribution | Privacy-preserving data sharing, machine learning research |
Case Study
Let’s delve into a practical case study that illustrates the application of data anonymization techniques. PsyAtlas, an innovative health app at the intersection of neuroscience, generative artificial intelligence, and psychosomatics, serves as our real-world example.9 The app aims to enhance health outcomes through a holistic approach, addressing symptoms and pains often prone to misdiagnosis or mistreatment.
Currently in a pre-trial phase with invitation-only access, PsyAtlas employs a unique self-diagnosing tool. This tool connects specific pain points in the body with potential underlying reasons, incorporating a blend of physical and emotional aspects. For instance, shoulder pain might be linked to an unresolved personal issue, such as a disagreement with a business partner, causing one to feel a metaphorical “weight to carry.” The app employs a pre-trained AI to provide insights and solutions, guiding users through a recovery process.
To ensure inclusivity, the in-app AI assistant engages patients by asking therapeutic questions and explaining solutions. If needed, human professionals are available for further assistance. However, the app collects sensitive patient information, including names, email addresses, age, sex, medical conditions, and psychological conflicts. In cases where patients consent to video calls, these interactions are recorded, transcribed, and utilized by a machine learning algorithm to enhance future diagnoses.
This extensive data collection and processing trigger privacy concerns, necessitating compliance with stringent requirements. PsyAtlas founders, recognizing the need to share and combine patient data for research and treatment, opted for data anonymization techniques. Specifically, they chose randomization as their anonymization method. This technique introduces noise into the database by adding random values or perturbing existing ones, such as swapping ages. This strategic approach aims to make it challenging to identify individuals while still allowing for meaningful machine-learning analyses.
Future Trends in Data Anonymization
As technology evolves and privacy concerns continue to grow, data anonymization techniques will also advance. Some future trends to watch out for include:
- Advancements in privacy-preserving technologies
Ongoing innovations in data anonymization, including secure enclaves and federated learning, will significantly enhance the overall effectiveness of safeguarding sensitive information, ensuring a more robust approach to privacy preservation. - Machine learning and anonymization
The integration of machine learning models and techniques is poised to play a more significant role in automating and refining data anonymization processes. This evolution aims to strike a better balance between privacy and utility, as exemplified by the privacy gradient and chart, showcasing the ongoing synergy between machine learning and enhanced data anonymization. - The role of AI in data protection
AI serves a dual role in the realm of data protection and anonymization. On the positive side, advanced AI techniques, such as differential privacy algorithms, play a pivotal role in safeguarding sensitive information by providing anonymized results to queries. However, this same power of AI poses a considerable risk when used maliciously, especially in cases where robust anonymization techniques like differential privacy are not employed. In such instances, data becomes vulnerable to exploitation by AI-driven methods or malicious users seeking to re-identify individuals and compromise the privacy safeguards in place. The challenge lies in striking a delicate balance between leveraging AI and implementing stringent security measures to stop malicious attempts at data re-identification.
Conclusion
Anonymization is one of the greatest ways to ensure the safety of data you collect. This additional layer of security lets you freely exploit your data collection in ways that would be legally restricted when dealing with non-anonymized data. While challenges exist, best practices, tools, and legal frameworks have been developed to ensure the effective implementation of data anonymization. Nevertheless, there are also some considerable benefits of using personal data in its pure original form. That’s why you need to think through the pros and cons of each option before making a final decision. Regardless of the chosen method, it is crucial to bear in mind that maintaining a secure data storage environment remains of utmost significance (refer also to Best Practice in data anonymization).
Real-time Analytics with PVML
PVML allows analysts to dive into real-time, online analytics data without the worry of compromising privacy. This is done with mathematical models and Differential Privacy.
The contents of this article are intended solely for educational purposes, offering general information on legal, commercial, and related subjects. It does not constitute legal advice and should not be construed as such. The information provided may not be the most current or up-to-date.
The information in this article is presented “as is” without any express or implied representations or warranties. We explicitly disclaim all liability for actions taken or not taken based on the contents of this article.
If you have specific questions regarding any legal matter, it is recommended to consult with your attorney or seek guidance from a professional legal services provider.
Additionally, this article may include links to third-party websites for the convenience of the reader, user, or browser. However, we do not endorse or recommend the contents of any third-party sites.
2 https://www.iso.org/obp/ui/#iso:std:iso-iec:29100:ed-1:v1:en
3 This Working Party was set up under Article 29 of Directive 95/46/EC. It is an independent European advisory body on data protection and privacy. Its tasks are described in Article 30 of Directive 95/46/EC and Article 15 of Directive 2002/58/EC.
4 https://ec.europa.eu/justice/article-29/documentation/opinion-recommendation/files/2014/wp216_en.pdf
5 Kris Kuo, “You can be identified by your Netflix watching history”, 31 July 2020, Artificial Intelligence in Plain English, https://ai.plainenglish.io/ahh-the-computer-algorithm-still-can-find-you-even-there-is-no-personal-identifiable-information-6e077d17381
6 Cynthia Dwork, “Differential Privacy” (Microsoft Research, 2006), https://www.microsoft.com/en-us/research/publication/differential-privacy/
7 Katharine Jarmul, Practical Data Privacy, O’Reilly 2023.
8 How likely is it to preserve natural data structure/distribution
9 https://psyatlas.com









