What is Data Masking?
If you’re planning to share data with third parties for analysis, it’s important to make sure that the data cannot be linked back to its owner.
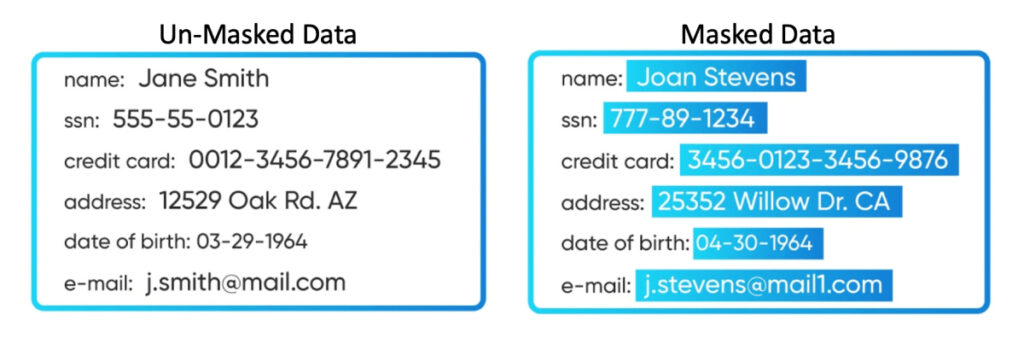
You need to ensure that any personally identifiable information (PII) is not visible to third-party users when interacting with the data.
This is done to make sure that you’re compliant with standards such as GDPR and HIPAA.
This can be accomplished by data masking. Data masking is the process of obscuring or masking specific data elements within a dataset to protect sensitive information.
Simply put, data masking is used in situations where the data is being shared or used for analysis, but certain elements of the data need to remain confidential.
In this way, the privacy of your data is preserved as sensitive information is not shared with unauthorized users, but the data is still usable for meaningful analysis.
Use Cases of Data Masking
Data masking is used in various domains.
Software Development
Developers and testers need accurate data when they build the application to ensure that the software performs as expected under realistic conditions.
However, using actual sensitive data, such as personal customer information, poses a privacy risk as a developer environment is often shared across multiple dev teams and could potentially expose PII.
Therefore, the actual data is still used, but the personal information is masked, ensuring that the usefulness and integrity of data for testing purposes are maintained.
Third-Party Data Sharing
Certain organizations share data with third-party companies for analysis. For example, you might have seen the following statement in most of the privacy policies that you see:
We never sell your information, but we do share some information about you with third parties, such as partners and service providers.
In such cases, organizations must ensure that the data is shared in a way where the personal information is not visible to the third party. So, companies usually mask the PII data by obscuring it before sharing it, thus protecting privacy while still allowing third parties to work effectively with the data.
Process Outsourcing
Sometimes, companies outsource certain aspects of their business. For instance, many companies choose to outsource auditing and human resource needs to external firms. In such cases, companies often have to disclose sensitive data, such as payments.
Now, it would be problematic if the employee’s name and email were shared along with their salary. Therefore, in these cases, sensitive information such as their name and email is masked to preserve privacy while still letting the outsourced parties perform the allocated tasks.
Compliance
Most organizations function in industries that impose strict data protection, such as GDPR and HIPAA, that mandate the safeguarding of personal and sensitive data.
Companies must adopt data masking strategies to comply with these regulations to ensure that sensitive data is not exposed, even to internal users who do not have a clear need to know.
Approaches for Data Masking
There are several ways to mask data.
Nulling
Nulling involves replacing sensitive data fields with null values or blanks.
It’s the simplest form of data masking and can be used when the presence of a value is sensitive, but the actual value itself is not necessary for the process or analysis at hand.
For instance, consider the dataset:

This dataset includes personal and professional details of employees, such as names, contact information, salaries, and performance ratings. So, if this data was shared with a dev team that’s working on an HR system, you could use Nulling as the information that’s present is sensitive but not necessary for the actual analysis.
So, the masked dataset with nulling would look like this:

As shown above, sensitive information such as email, phone number, salary, and performance rating has been NULLed out, and only data relevant for analysis is present.
Anagramming
Anagramming simply jumbles the characters of a field to create a nonsensical string that maintains the original format but doesn’t convey the original information.
This is useful for text data where the format needs to be preserved for system compatibility, such as usernames or codes, but where the actual text should not be discernible.
For instance, consider the dataset:
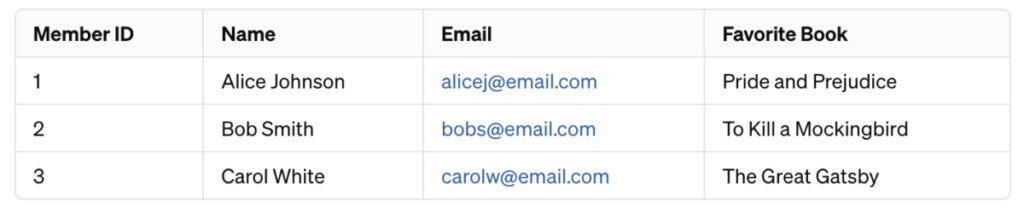
For a system, email addresses need to be formatted properly. Such values can be masked using anagramming to create the output:
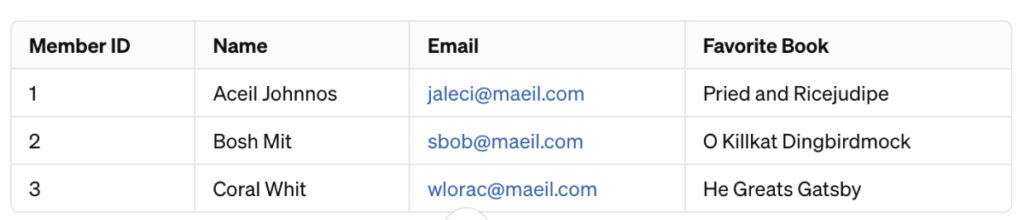
As you can see, all three fields – name, email, and favorite book – have been anagrammed.
Substitution
Substitution replaces sensitive data with non-sensitive but realistic-looking data. These substitutions are often chosen from a list or dictionary that matches the format of the original data but has no direct link to the original data points.
This is useful for names, addresses, and phone numbers in environments like testing and training, where the realness of data is important.
For example, consider the dataset:

This database stores the customer’s name, address, and credit card number. Sharing the credit card number and their address in a dev environment would be a potential privacy risk.
So, it can be substituted instead:

As you can see, the following has been made:
- Name: Real names are replaced with other names that have no connection to the original individuals.
- Address: Real addresses are replaced with plausible addresses that do not correspond to the actual locations of the customers.
- Credit Card Number: Real credit card numbers are replaced with fake numbers that follow the correct format but are invalid for transactions.
If you’re using substitution, ensure the substituted values are realistic enough to maintain the integrity of data-driven processes.
Encryption
This is a reversible form of data masking, while the other techniques are irreversible.
Encryption masks data by converting the original data into a coded format using an algorithm and a key.
Only those with the key can decrypt the data to reveal the original information.
Financial institutions and healthcare providers use encryption to ensure that customer data, financial records, and personal health information are securely stored and transmitted.
For instance, consider this dataset:
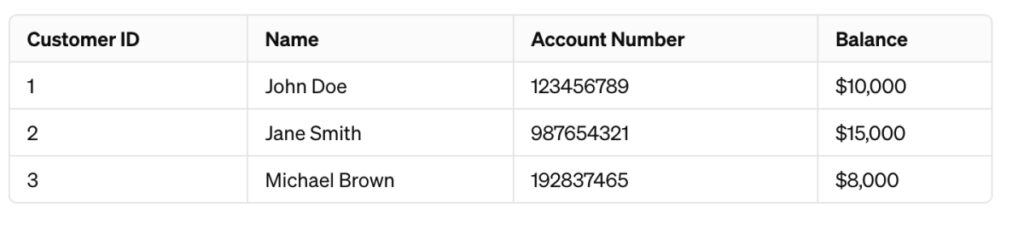
Sharing the account numbers and balances is quite sensitive. So, you could encrypt it:

Data Masking Best Practices
Consider the following when masking data:
- Understand the data: Clearly identify which data needs to be masked, including personally identifiable information (PII), protected health information (PHI), financial details, and other sensitive elements. Additionally, determine if your masked data would need to be reversed at some point.
- Use the right technique: Based on your dataset and use case, ensure that you choose the right data masking technique. For example, don’t use NULLing if your goal is to replicate data on test environments.
- Use automation: Use automated data masking tools to apply masking consistently and efficiently across large datasets.
Concluding Thoughts
Always ensure that you understand the domain you’re working on and the governing bodies you have to comply with and make sure that you mask your data effectively to preserve data privacy.