Differential privacy is a statistical technique used to ensure the privacy and confidentiality of individuals’ data when being used in broader analyses or shared publicly. It achieves this by adding controlled random noise to the data to mask the contribution of individual data points, making it difficult to derive anything specific about the individual from the output.
Differential privacy can be categorized into 3 main variants based on the different theoretical frameworks and privacy guarantees they offer:
- Approximate differential privacy
- Rényi differential privacy
- Hypothesis Test Differential Privacy
Each of these variants is designed to address specific concerns related to the trade-offs between privacy protection and data utility.
1. Approximate Differential Privacy
In standard differential privacy, outputs almost don’t change based on whether or not any individual’s data is included or excluded from the dataset. This small variance is denoted by ϵ, and the probability of finding information about an individual will decrease as the value for ϵ gets small.
Approximate Differential Privacy (ADP) modifies the standard differential privacy model by introducing a small probability of error, denoted as δ (delta). It makes working with data more practical, especially when strict privacy rules make it too hard or limit what you can learn from the data.
How Approximate Differential Privacy Works
Assume that you need to find a region’s median salary while ensuring the privacy of individual data. To implement ADP, you can use Laplace or Gaussian distribution mechanisms.
- Step 1 – Define how much the median income can change if one individual’s data were added or removed. Eg: Δf=500 dollars.
- Step 2 – Choose a smaller ϵ for tighter privacy(ϵ=0.5).
- Step 3 – Select a very small δ, like 0.01, to exceed the privacy guarantee set by ϵ.
- Step 4 – Calculate the standard deviation (σ) for Gaussian noise using the below equation.
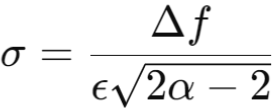
mport numpy as np # Constants delta = 0.01 epsilon = 0.5 Delta_f = 500 # Calculate sigma sigma = (np.sqrt(2 np.log(1.25 / delta)) Delta_f) / epsilon
- Step 5 – Generate a noise value from a Gaussian distribution with mean 0 and the calculated standard deviation. Add this noise to the actual median income.
median_salary = 50000 noise = np.random.normal(0, sigma) noisy_median_salary = median_salary + noise
Advantages
- Offers more flexibility when privacy constraints are strict.
- Provides higher data utility.
Disadvantages
- There’s a small probability (δ) that the privacy protection could fail.
- Difficult to understand with dual parameters (ϵ and δ).
2. Rényi Differential Privacy (RDP)
In data analysis, performing queries on the same dataset can slightly compromise data privacy on each access. These small leaks can accumulate, posing a risk of significant privacy loss over time.
Rényi Differential Privacy (RDP) addresses this issue by using Rényi entropy, which adjusts its sensitivity with an order parameter (α):
- Lower α values focus on worst-case scenarios, applying stricter privacy measures to safeguard against rare, significant leaks.
- Higher α values provide a balance, focusing on general cases and maintaining overall privacy without excess conservatism.
RDP tracks the privacy “spent” on each query, ensuring the cumulative cost stays within a predefined privacy budget. This makes it ideal for complex, iterative tasks requiring repeated data access.
How Rényi Differential Privacy Works
Consider a scenario where a data analyst needs to publish statistics from a dataset after each iteration.
- Step 1 – Define the sensitivity (Δf) of the function.
- Step 2 – Choose an order (α) and a corresponding ϵ(α). Eg: α=2 and ϵ(2)=1.
- Step 3 – Establish an initial privacy budget (Γ).
- Step 4 – Calculate the standard deviation (σ) of the Gaussian noise based on the chosen α and ϵ(α).
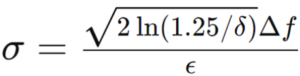
- Step 5 – After each iteration, update the privacy budget by subtracting the privacy cost of that iteration.
import numpy as np alpha = 2 epsilon = 1 # Epsilon for the current release Gamma = 5 # Total privacy budget Delta_f = 500 # Sensitivity of the query # Calculate the SD of the noise sigma = Delta_f / (epsilon np.sqrt(2 alpha - 2)) median = 50000 noise = np.random.normal(0, sigma) noisy_median = median + noise # Update the privacy budget Gamma -= epsilon
Advantages
Provides more precise control over privacy budgets.
Provide a clear view of privacy loss over multiple analyses.
Disadvantages
Understanding and selecting appropriate α and ϵ values can be challenging.
3. Hypothesis Test Differential Privacy
Hypothesis Test Differential Privacy (HTDP) measures privacy in terms of a hypothesis test’s ability to distinguish whether a dataset’s output came from one dataset or another. It uses the concepts of Type I and Type II errors for decision-making.
How Hypothesis Test Differential Privacy Works
Suppose a school wants to publish an exam’s average score without compromising individual students’ privacy.
Step 1 – Define Hypotheses
Null Hypothesis (H0): The published average score remains unchanged whether a student’s score is added or removed, suggesting minimal individual impact.
Alternative Hypothesis (H1): The published average changes significantly when a student’s score is added or removed, indicating potential privacy breaches.
Step 2 – Determine Acceptable Error Levels
Set acceptable levels for Type I errors (false positives, wrongly rejecting H0) and Type II errors (false negatives, failing to reject H0) based on the desired privacy standards.
Step 3 – Design and Implement Privacy Mechanism
After establishing error thresholds, implement a noise addition mechanism:
- Choose a Noise Distribution: Use the Laplace distribution for its balance between privacy and data utility.
- Calculate the Noise Scale: For a class of 100 students with scores from 0 to 100, removing the highest score (100) could shift the average by up to 1 point. With ϵ=0.5, the noise scale b is set as b= (1/0.5) = 2, meaning Laplace noise with a scale of 2 is added.
- Generate and Add Noise: The below method ensures the published average score is sufficiently obfuscated, making it hard to determine any individual student’s influence.
import numpy as np students = 100 true_scores = np.random.randint(50, 100, size=students) actual_average = np.mean(true_scores) sensitivity = 1 epsilon = 0.5 noise_scale = sensitivity / epsilon # b = Δf / ε noise = np.random.laplace(0, noise_scale) noisy_average = actual_average + noise
Conclusion
Differential privacy and its variants Approximate Differential Privacy (ADP), Rényi Differential Privacy (RDP), and Hypothesis Test Differential Privacy (HTDP), helps protect individual data while still allowing useful analysis. Each variant offers different benefits, balancing privacy and practicality. As privacy concerns continue to grow, understanding and applying these methods will become increasingly essential.