What is RAG?
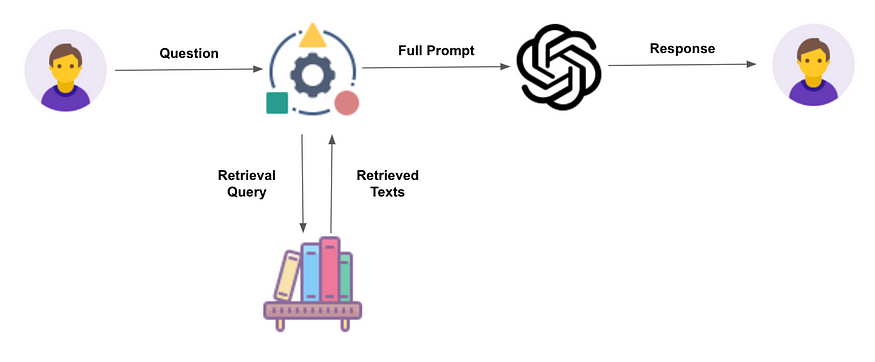
Retrieval-augmented generation (RAG) is an advanced technique in natural language processing (NLP) that aims to improve the performance of language models on tasks requiring access to external knowledge sources beyond what is contained in their training data. RAG systems access and process various external information sources to generate more comprehensive and informed responses, making RAG adaptable to different tasks and domains and allowing the model to generate more coherent and contextually appropriate responses.
Retrieval Sources for RAG
- Unstructured Text: This includes large collections of documents, textual databases and internal company documents, such as:
- Processes description
- Best practices
- Legal documents
- Task-specific guidelines
- Knowledge Graphs: Structured representations of facts and relationships between entities, offering a more organized way to access information and retrieve factual information about entities, relationships, and events.
- Code Repositories: For tasks involving code generation or understanding, RAG can leverage code repositories like GitHub.
- The Web: Search engines can be used to retrieve relevant web pages on-the-fly (e.g., Wikipedia articles, research papers, etc.), providing access to a vast amount of real-time information.
Enterprise Use Cases
- Customer Service: RAG can power chatbots that answer complex customer queries by retrieving relevant information from product manuals, FAQs, or past support tickets.
- Research and Development: Assist researchers by summarizing research papers, extracting key insights, and suggesting relevant studies from vast databases.
- Expert Systems: Build systems that offer expert advice in specific domains by retrieving and processing information from domain-specific knowledge bases.
Limitations and Challenges
While RAG offers significant potential, it also faces several limitations and challenges:
- Source Quality: The performance of RAG models is heavily dependent on the accuracy and relevance of the retrieved information. Ensuring the quality and relevance of source materials is crucial.
- Computational Cost: Retrieving and processing information from external sources can be computationally expensive, especially for large datasets.
- Explainability and Bias: It can be challenging to understand how RAG models arrive at their outputs, making it difficult to identify and mitigate potential biases present in the training data or source materials.
- Knowledge Integration: Effectively integrating the retrieved information with the language model’s outputs is a non-trivial task, as the model needs to learn to seamlessly blend the external knowledge with its own language generation capabilities.
Data Peace Of Mind
PVML provides a secure foundation that allows you to push the boundaries.

Benefits of RAG
- Enhanced Factual Accuracy: Access to external information sources improves the factual accuracy of generated text compared to standard language models.
- Domain-Specific Expertise: RAG systems can be adapted to specific domains by utilizing relevant knowledge sources, leading to more specialized and accurate outputs.
- Up-to-date Information: The ability to access real-time information through web search ensures that generated content is current and relevant.
- Improved Efficiency: Automating tasks like information retrieval saves time and resources for businesses and speed up time to value.
Future Directions
- Improved Retrieval Techniques: Developing more efficient and accurate methods for retrieving relevant information from large and diverse data sources.
- Multimodal RAG: Integrating information from various modalities like text, images, and audio to generate richer and more comprehensive responses.
- Personalized RAG: Tailoring the retrieval and generation process to individual user preferences and contexts.
- Responsible AI: Addressing ethical concerns related to bias, fairness, and transparency in RAG systems.
PVML & RAG
RAG models can be used to build more sophisticated question-answering systems, where the chat can retrieve relevant information from external sources to provide more comprehensive and accurate responses.
PVML uses RAG to securely connect with the organizational databases to unlock insights across the company’s data without requiring training or fine-tuning the model on the ever-changing data, thus enabling live insights alongside a playground to test the model’s performance.
PVML’s AI integration return the computation with each response to provide users with explainability and clarity on the type of resources used and what was retrieved from the databases in order to understand the reasoning behind the output.
To ensure privacy and security, PVML enforces the permissions defined on the platform prior to applying any computation on the database to make sure the response can only rely on the information that is available to the user querying the database, thus making sure the endless possibilities of AI integration continue to align with the company’s security and compliance requirements.