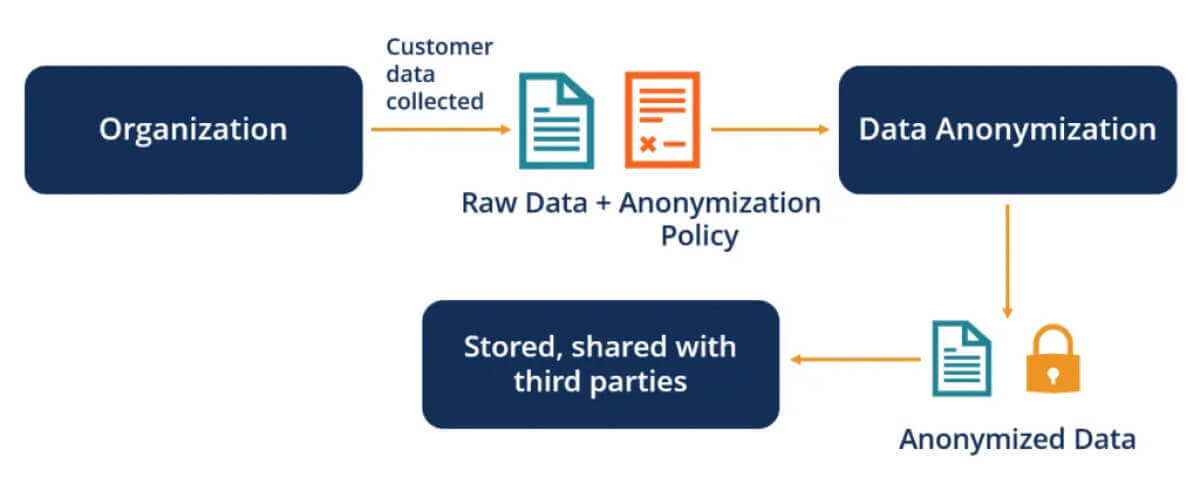
What is Data Anonymization?
All organizations that share data with third parties for analysis rely on some form of data anonymization. But you might wonder – “Why do they do that?” Simply put, organizations deal with a lot of user data, including PII (personally identifiable information) data. This could be a name, address, gender, blood type, salary, or other sensitive details that could be used to identify a user.
PII data are often anonymized to preserve user privacy, transforming them so that individuals can no longer be identified.
Challenges of Data Anonymization
Implementing data anonymization effectively presents several challenges. Here are some of the key issues:
1. Balancing Privacy and Utility
Organizations must walk a fine line between making data anonymous and keeping it useful. When data is overly anonymized, it can lose its utility for analysis and decision-making.
For example, consider a scenario in which you want to use patient data to study trends in heart disease. Before using and sharing the data, you anonymize it by
- Removing names
- Removing addresses
- Replacing date of birth and age with age ranges (30-50, 50-70)
- Generalizing address to a region
This dataset appears to be overly anonymized. This is because researchers might find it challenging to determine crucial trends with age as the range is too big or based on a location since it has been replaced with a region.
But, if too little anonymization is done, there’s a higher risk of identifying individuals. Finding a balance is crucial for maintaining both privacy and the value of the data.
2. Risk of Re-Identification
Despite anonymization, there’s always the risk of your PII data being re-identified in the analysis process.
For example, imagine a city government surveyed public transportation use, collecting data on thousands of residents, including:
- Age
- Gender
- Job industry
- Times they typically use public transport
To share this data with urban planning consultants without exposing individual identities, the city decides to anonymize it. They remove:
- Names
- Addresses
However, they leave other details like:
- Age
- Gender
- Industry
- Transport usage times.
Let’s assume this dataset included an entry for a 50-year-old male in the media industry who uses public transportation around 7:30 AM and 6:00 PM. Now, even though the names and addresses were anonymized, there’s still a risk of identifying this individual.
For example, he may be one of the few older males working in media in a smaller neighborhood, and someone familiar with that industry or area might easily deduce the individual’s identity if they know someone fitting that profile who commutes at those times.
So, there are cases where anonymized data can be re-identified if the right context is provided.
3. Compliance
Data protection laws such as GDPR and HIPAA set strict laws on data privacy and how PII should be handled.
These regulations tend to be updated frequently, and you also need to consider the data protection laws in your own country. As a result, organizations should plan for the continuous adoption of their data protection cycle to ensure they remain compliant.
4. Ethical Considerations
Anonymization often raises ethical concerns.
For example, imagine a school district that has collected detailed student data over several years, including:
- Academic performance
- Socioeconomic status
- Ethnicity
- Special education needs
The district decides to anonymize this data and share it with an educational research firm to help improve educational strategies and outcomes.
But, during anonymization, the district must decide how much information they should retain and how much to remove. If they overly generalize the data, they might prevent the research firm from identifying critical disparities in educational outcomes. However, if they don’t anonymize the data sufficiently, there’s a risk of exposing sensitive information about individual students, potentially leading to discrimination.
The school must consider a fine line before proceeding with anonymization while balancing the privacy of individual students with the public interest in improving education.
5. Technical Complexity
Data anonymization is not easy to implement. There are several anonymization techniques with various levels of complexity and use cases.
For instance, algorithms like k-anonymity are complex to implement and must be tailored to each specific dataset and use case.
Therefore, the team must be skilled in data anonymization, capable of understanding the technique, and able to verify whether it is appropriate for a dataset before proceeding.
Conclusion
Data anonymization is a vital process in preserving user privacy. If data is not anonymized before it is shared, user privacy could be compromised, significantly impacting an organization’s reputation and potentially leading to data breaches and lawsuits.
However, there are significant challenges when implementing data anonymization within an organization. Organizations must navigate complex technical, legal, and ethical landscapes to effectively anonymize data.
By doing so, they can guarantee data security and provide data that’s useful for analysis.